A Visual Introduction to Prompt Engineering
By the team at Vana.
This is an image.
You may recognize it as "Vertumnus", an oil painting created by Giuseppe Arcimboldo in 1591.
For a human, recognizing this image is a simple task. But how does a computer recognize Vertumnus?
Consider the overlayed, computer-generated text description, which was made by CLIP, a neural network that was trained to recognize images.
There are some things that the computer can recognize, like the fact that the painting's subject has fruits and vegetables on his head, and that the portrait was painted by Giuseppe Arcimboldo.
But there are some things the model gets wrong, like its guess that Arcimboldo's subject was Breaking Bad's Walter White.
Regardless of its quirks, this text output tells us a lot about how a computer thinks. We can notice common phrases, and the elements that a computer thinks are important.
Learning the language of computers is a good first step to a new and growing field of work: prompt engineering.

a portrait of Nicolas Cage in the style of...
a painting of a person with fruit and vegetables on their head, by Giuseppe Arcimboldo, arcimboldo giuseppe, giuseppe arcimboldo walter white, inspired by Giuseppe Arcimboldo, by Arcimboldo, inspired by Arcimboldo, by Lucas Cranach the Younger, by Lucas Cranach the Elder
What if we could use AI's own imagination to create new images?
Prompt engineering is the process of creating a prompt that will effectively guide an AI model to produce a desired output.
Consider a simple prompt, given to a popular image generation model, DALL-E:
> "a man wearing a red shirt."
This prompt will produce an image, but is it exactly what you had in mind?

Maybe, but most likely not. If you were to ask the model to produce something closer to your imagination, you would need to be more specific. Perhaps you could request a certain pose, or a certain background, or a certain facial expression. You could also specify the the style of the image: is it a painting, a photograph, or a cartoon?
A better prompt would be:
> "a pencil and crayon image of a happy man wearing a red polo, close up on his face, with a blue background."
Depending on what you had envisioned, this was likely much much closer to what you had in mind.




These details are the crux of prompt engineering. The more specific you are, the more likely the model will produce an image that meets your expectations. And without knowing the details of the model's architecture, it's impossible to know exactly what information it needs to produce a desired output.
Back to Vertumnus.
We can use this image—or rather, what the computer sees in this image—to illustrate prompt engineering at work.
Let's focus on the text description. If you fed this text description, and only this text description, to a model like DALL-E (the one that produced the red shirt images above), what would it generate?
Something like this:



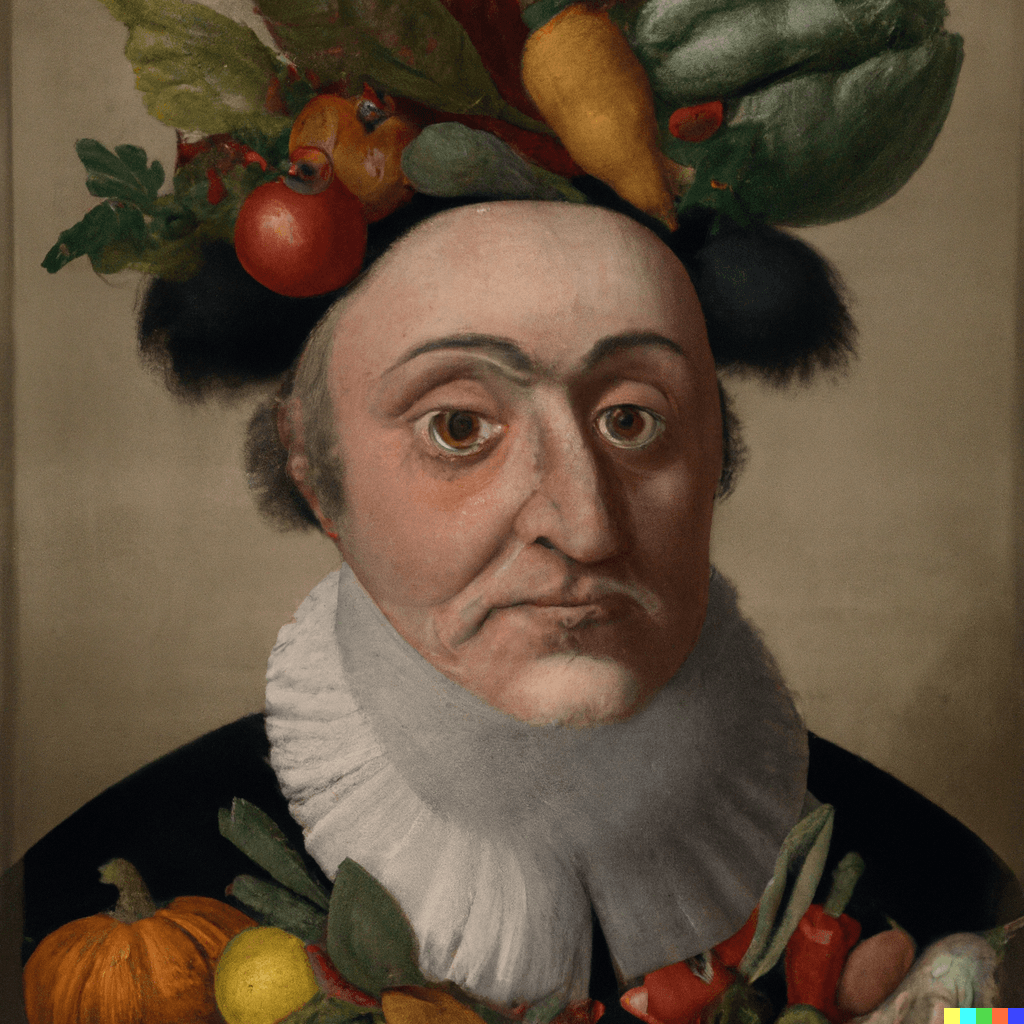
Here's another question: what if we instructed the model to create a new image of someone else, entirely, in the style of Vertumnus?
Let's add the following phrase as a prefix to the text description: "a portrait of Nicolas Cage in the style of..."
The result (generated with LoRA) is a glorious mix of Vertumnus and the new subject (in our case, Nicolas Cage).
We've combined an existing image description (of Vertumnus) with a new subject (Nicolas Cage).
In doing so, we've used a machine-generated image description to create a prompt that most effectively produces the desired output.
a portrait of Nicolas Cage in the style of...
a painting of a person with fruit and vegetables on their head, by Giuseppe Arcimboldo, arcimboldo giuseppe, giuseppe arcimboldo walter white, inspired by Giuseppe Arcimboldo, by Arcimboldo, inspired by Arcimboldo, by Lucas Cranach the Younger, by Lucas Cranach the Elder
Try it out for yourself 👇
Upload an image of your desired style. Then, create a brand new portrait of yourself (or a celebrity) in this style!
(or select one)



